Processus de développement 2TUP
2TUP est un processus de développement logiciel qui implémente le processus unifié. Chacune des étapes du cycle découle des précédentes.
| Le cycle en Y |
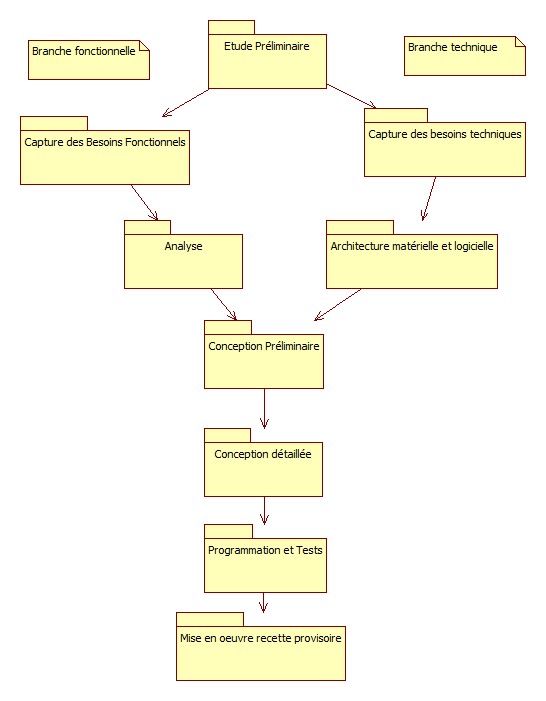
La méthode est par ailleurs incrémentale: à partir de la capture des besoins fonctionnels, on définit plusieurs cas d'utilisation représentant chacun un incrément du cycle de développement.
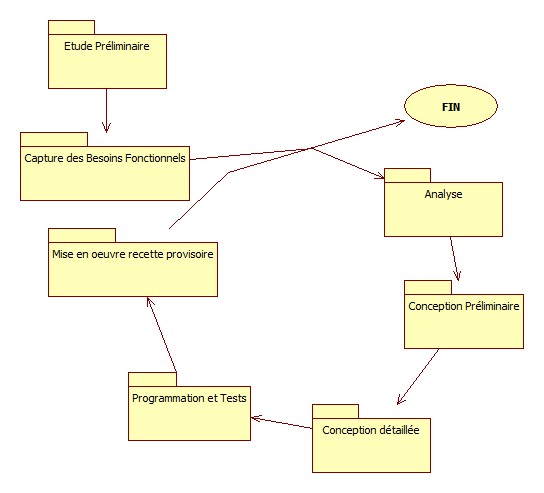
| Le cycle d'un incrément |
| Etude préliminaire |
Un document doit être rédigé contenant les paragraphes suivants:
- Présentation du projet: Il s'agit de reformuler le besoin tel qu'il a été exprimé dans le cahier des charges.
- Définition des grands choix techniques: matériels, logiciels, langages, architecture, méthodes utilisées.
- Recueil des besoins fonctionnels: il s'agit de recenser les traitements informatiques prévus.
- Recueil des besoins opérationnels: il s'agit d'expliciter les volumes et la définition de la sécurité.
- Acteurs du système: ce paragraphe recense les acteurs et précise les prérogatives de chacun.
- Diagrammes de contexte: un diagramme de contexte statique représente les acteurs du projet de façon structurée; un diagramme de contexte dynamique représente les messages échangés entre le système d'information et les acteurs (sous le diagramme apparait chaque message avec les attributs qu'il contient).
Ce document devra être validé par le commanditaire du projet avant de passer à la suite.
| Capture des besoins fonctionnels |
Un document doit être rédigé contenant les paragraphes suivants:
- Liste des cas d'utilisation
- Description des cas d'utilisation
- Structuration en packages
Liste des cas d'utilisation: obtenue à partir du diagramme de contexte dynamique de l'étude préliminaire. Il y a un cas d'utilisation pour chaque message externe entrant.
Description des cas d'utilisation: pour chacun des cas d'utilisation trouvé dans le paragraphe précédent, on va documenter ce qui suit.
|
Préconditions: conditions qui devant être préalablement remplies pour que le cas d'utilisation puisse fonctionner. Enchainements: étapes devant être suivies par l'acteur pour arriver à la fin du cas d'utilisation. Exceptions: description de chaque exception. Postconditions: conditions dans lesquelles se trouve le système après exécution du cas d'utilisation. Besoins d'IHM: exigences de présentation et d'action en matière d'interface, concepts généraux qui ne sont pas exprimés dans les enchainements. Contraintes non-fonctionnelles Confidentialité: accès au système. Fréquence de cas d'utilisation: plusieurs fois par jour, journalière, hebdomadaire, mensuelle... Disponibilité: plages horaires et jours de la semaines où ce cas d'utilisation est disponibles. Concurrence: mentionner les acteurs ayant les mêmes prérogatives. Intégrité: ensemble d'activités accomplies par le même acteur dans un même processus. Volumétrie: nombre d'acteurs; Nombre de messages par unités de temps; Diagrammes Diagramme d'activité: diagramme où chaque ovale désigne un enchainement précédement décrit. Chaque ovale est suivi par un losange de tests derrière lequel des évènements conduisent à d'autres enchainements. Diagramme de séquence: représente les échanges de messages entre l'acteur et le système. Ce diagramme est lui aussi conçu à partir des enchainements précédement décrits. Diagramme de classes participantes: les classes participantes sont obtenues à partir des propriétés ou attributs manipulés par le cas d'utilisation. Ces classes sont appelées des classes "métier".
|
Structuration en packages: lorsqu'il y a de nombreux cas d'utilisation, il est utile de les grouper par packages selon les thématiques.
Le descriptif de chacun des cas d'utilisation doit être soumis pour validation. Les responsabilités mutuelles sont engagées. Restent à définir avec le responsable utilisateur du projet les incréments de développement (un ou plusieurs cas d'utilisation par incrément).
Il est nécessaire de désigner les cas d'utilisation les plus importants pour la première itération. Les autres cas seront traités dans les incréments de développement suivants, selon leur degré d'importance.
| Analyse |
Cette étape est une étape clé du processus. Elle va permettre une ébauche de la structure objet du projet et doit donc être réalisée avec soin. A nouveau, un document devra être écrit contenant les phases suivantes:
- Regroupement en catégories
- Développement du modèle statique
- Réalisation des cas d'utilisation
- Création des classes frontières, controleurs et collections d'objets métier
- Responsabilités des classes
Regroupement en catégories: les classes qui ont une forte dépendance ou connectivité sont regroupées dans une catégorie, et cela lorsque les classes et les associations sont nombreuses. En UML il s'agit d'un package, adapté aux classes. Au-delà d'une quinzaine de classes, le regroupement en catégories s'impose.
Dans ce paragraphe, indiquer le nom de chaque package et créer un diagramme de classes incluant l'ensemble des classes le composant. Il faut pour cela se baser sur le diagramme de classes participantes du dossier précédent.
Développement du modèle statique: cette étape est très importante. Il va s'agir de raffiner les associations et les classes. Pour cela, on se pose plusieurs questions:
- Un objet de la classe 1 est-il composé d'un ou plusieurs objets de la classe 2? Si oui alors l'association est une agrégation.
- Est-ce que le cycle de vie des objets de la classe 2 dépend de celui des objets de la classe 1? Si oui alors l'agrégation est une composition.
- Est-ce qu'on objet de la classe 1 est une sorte d'objet de la classe 2? Si oui alors on parle de généralisation ou spécialisation et cela débouchera sur la notion d'héritage lors de la conception.
On va aussi raffiner les attributs des classes: certains attributs peuvent être calculés à partir d'autres et sont alors transformés en opérations (exemple: puttc() = puht x TVA).
On va assigner la visibilité des attributs et opérations des classes: de façon générale, les attributs sont privés et les opérations publiques.
On va procéder au typage des attributs et opérations.
Dans le document, on va écrire le dictionnaire de données: il s'agit de lister l'ensemble des attributs de l'application. On fournit les informations suivantes: nom, type, ensemble de valeurs valides (plages), la classe à laquelle il appartient, la description et le mnémonique à utiliser en programmation.
On va aussi inclure un nouveau diagramme global de classes métier après raffinement.
Puis pour chaque cas d'utilisation, fournir un diagramme de classes métier utilisées par ce cas.
Réalisation des cas d'utilisation: indiquer quels sont les cas d'utilisations qui vont être réalisés lors de l'incrément auquel ce document appartient. On insère donc un diagramme des cas d'utilisation représentant ceux qui sont réalisés.
Création des classes Frontière, Contrôleur et Classes Collections d'objets métier: pour chaque cas d'utilisation, on crée une classe frontière et une classe contrôleur. Les classes collection sont utilisées lorsqu'on doit manipuler des ensembles d'objets. On le déduit de la lecture des enchainements du cas d'utilisation.
Responsabilités des classes:
- La classe frontière correspond à l'IHM, elle affiche et reccupère des informations.
- La classe contrôleur gère la logique du cas d'utilisation, fait l'articulation entre la frontière et les classes métiers.
- Les classes métier ont pour responsabilité de base de charger et sauvegarder un objet
- Les classes collection ont pour responsabilités minima de charger et sauvegarder des listes d'objets et retrouver un objet dans la liste
Il est possible que certaines prérogatives de base ne soient pas utilisées dans les cas d'utilisation. Les autres responsabilités (opérations) sont déduites de la lecture des enchainements selon la démarche suivante:
- Tout composé est responsable de ses composants
- L'association et ses multiplicités indiquent les responsabilités avec l'objet voisin par collaboration.
- Sont éliminées les responsabilités qui ne sont pas utilisées et incorporées les listes utilisées dans les cas.
Création de diagrammes de séquence pour chaque cas d'utilisation:
- on reccupère les diagrammes de séquence créés antérieurement entre l'acteur et le système
- on remplace le système par l'objet frontière, l'objet controleur et les objets métiers et collections participants
L'objet controleur initie les échanges. A partir de ce moment, et en respectant les messages précédement décrits, on en déduit les échanges entre les différents objets en respectant les concepts de complétude (tout objet est complet et a tous ses attributs valués) et universalité (toute demande faite à un objet composant passe par l'objet composé).
Au fur et à mesure qu'on rajoute des messages aux diagrammes, on rajoute les opérations correspondantes et les paramètres convenables aux objets frontière, contrôleur, métier et collections.
| Conception détaillée |
Obtenir ce qui suit:
- Les scripts de génération de la base
- Diagrammes de composants
- Confection de l'IHM
- Ecriture du pseudocode
Les scripts de génération de la base: ils sont déduits des classes métiers.
Diagrammes de composants: ils sont construits à partir des diagrammes de classes participantes avec pour objectif d'assigner des rôles aux relations entre les classes lorsque cela est nécessaire (lorsque, dans la logique du cas d'utilisation, un objet a besoin d'avoir un autre objet en référence).
Confection de l'IHM: à ce stade, une ébauche de l'IHM peut être obtenue.
Ecriture du pseudocode: le pseudocode est écrit à partir de chaque message entrant des diagrammes de séquence de l'étape précédente. Il n'est pas nécessaire (on peut passer à la programmation directement).